

Data Engineering
- Home
- Data Engineering
Data Engineering
What is Data Engineering?
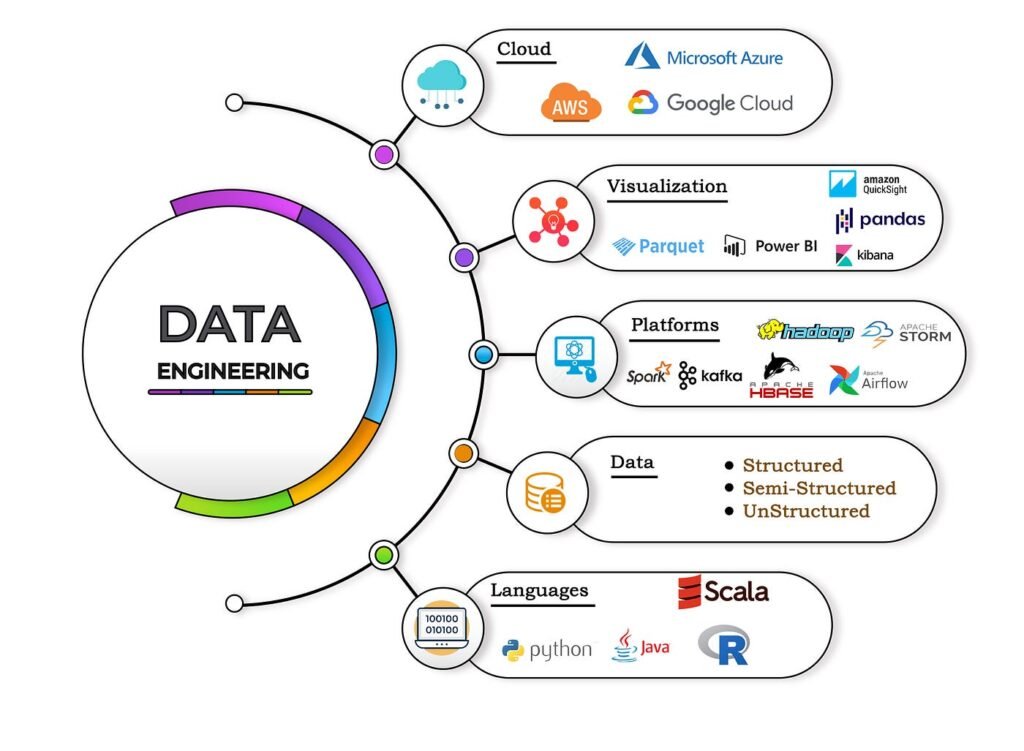
Data Engineering is the discipline of designing, building, and maintaining systems and infrastructure for collecting, storing, processing, and analyzing large sets of data. It focuses on the creation of data pipelines that ensure data is reliable, accessible, and usable for analysis, machine learning, and decision-making.

Key Components of Data Engineering
Data Collection:
- Involves gathering data from various sources, such as databases, APIs, IoT devices, and third-party platforms.
- Tools: Apache Kafka, Apache NiFi, and AWS Glue.
Data Storage:
- Storing data in a structured, semi-structured, or unstructured format for easy access and scalability.
- Types:
- Relational Databases (SQL): MySQL, PostgreSQL.
- NoSQL Databases: MongoDB, Cassandra.
- Data Lakes: AWS S3, Google Cloud Storage.
- Data Warehouses: Snowflake, Amazon Redshift, Google BigQuery.
Data Processing:
- Transforming raw data into a usable format through cleaning, organizing, and enriching processes.
- Batch Processing: Hadoop, Apache Spark.
- Real-Time Processing: Apache Flink, Kafka Streams.
Data Pipeline Design:
- Building workflows that automate the movement of data from source to destination (e.g., data lakes, data warehouses).
- Tools: Apache Airflow, Luigi, Prefect.
Data Integration:
- Combining data from various sources into a unified view.
- Tools: Talend, Informatica, dbt.
Data Security and Governance:
- Ensuring data is protected and compliant with regulations like GDPR and CCPA.
- Tools: Apache Ranger, AWS IAM.
Skills Required for Data Engineering
Programming Languages:
- Python: For scripting and data manipulation.
- SQL: For querying and managing relational databases.
- Java/Scala: For working with big data frameworks like Spark.
Big Data Technologies:
- Hadoop, Apache Spark, Apache Kafka.
Database Management:
- Expertise in both SQL (PostgreSQL, MySQL) and NoSQL (MongoDB, DynamoDB).
ETL (Extract, Transform, Load) Tools:
- Talend, Informatica, AWS Glue.
Cloud Platforms:
- AWS, Google Cloud Platform, Microsoft Azure for data storage and processing.
Data Modeling:
- Designing schemas and optimizing data storage for analytics.
Version Control and Collaboration:
- Git for versioning code and workflows.
Responsibilities of a Data Engineer
- Design and implement scalable data pipelines.
- Ensure data quality and consistency across systems.
- Optimize databases and data storage systems for performance.
- Collaborate with data scientists, analysts, and other stakeholders to meet business requirements.
- Monitor and maintain data workflows to ensure reliability and uptime.
- Implement data governance, security, and compliance measures.
Tools and Technologies in Data Engineering
Data Ingestion:
- Apache Kafka, Apache NiFi, AWS Glue.
Data Processing:
- Batch Processing: Hadoop, Apache Spark.
- Streaming Processing: Apache Flink, Storm.
Data Storage:
- Relational Databases: MySQL, PostgreSQL.
- NoSQL Databases: MongoDB, Cassandra.
- Cloud Storage: AWS S3, Google Cloud Storage.
Orchestration and Workflow:
- Apache Airflow, Prefect, Luigi.
Data Warehousing:
- Snowflake, Redshift, Google BigQuery.
Data Visualization (collaboration with analysts):
- Tableau, Power BI, Looker.
Why is Data Engineering Important?
Data Accessibility:
- Ensures that high-quality data is available for business intelligence and analytics.
Scalability:
- Handles the exponential growth of data and provides infrastructure that scales efficiently.
Foundation for Data Science and Machine Learning:
- Prepares and structures data for advanced analytics and predictive modeling.
Business Value:
- Drives decision-making by enabling access to actionable insights.
Emerging Trends in Data Engineering
Cloud-Native Data Solutions:
- Increased adoption of cloud services for data storage and processing (e.g., AWS, Azure, GCP).
Real-Time Data Processing:
- Growing demand for real-time analytics and decision-making using tools like Kafka Streams and Apache Flink.
DataOps:
- Focus on automating and streamlining the data lifecycle for improved efficiency and quality.
Serverless Data Pipelines:
- Tools like AWS Lambda and Google Cloud Functions allow for event-driven, serverless workflows.
AI and ML Integration:
- Data engineers are increasingly involved in preparing data pipelines for machine learning models.
Career Opportunities in Data Engineering
Roles:
- Data Engineer
- Big Data Engineer
- ETL Developer
- Data Architect
- Machine Learning Engineer (Data Pipeline Focus)
Industries:
- Finance, Healthcare, Retail, Technology, E-commerce, Media.
Salary:
- Competitive, with demand steadily increasing due to the rising importance of data in decision-making.